

Placing LLM-driven agents into text-based environments—like MUDs or interactive fiction games—lets us study survival, exploration, and puzzle solving in worlds that are entirely described in text. These environments are natural testbeds for reasoning because they strip away graphics and physics, leaving only words. By wiring agents to observe, decide, and act through constrained tools, we can benchmark problem-solving strategies while ensuring safety, reproducibility, and auditability.

Problem Statement
Text-first worlds—whether classic adventure games or multi-user dungeons (MUDs)—are perfect laboratories for agent reasoning. They offer rich environments fully described in words: every location, puzzle, or enemy is presented as text. That means agents must parse, plan, and act purely in language.
For example: “You are in a dimly lit cavern. A locked door blocks your way. To the north, a faint breeze whispers.”
Should the agent search for a key, push the door, or explore the breeze? These games pose challenges that directly align with what LLMs excel at: understanding and generating text.
They also offer depth of complexity. Unlike purely deterministic simulations, text games often hide affordances behind language. The player must guess, reason, and experiment—mirroring real-world problem-solving in a simplified but meaningful form. That makes them ideal for studying how AI agents cope with ambiguity, incomplete information, and creative inference.
Why Text Worlds for Agents?
Unlike robotics or 3D environments, text worlds are cheap to run, deterministic in baseline mechanics, and fully observable through logs. They:
Provide structured puzzles and goals (survive, escape, solve, explore).
Require long-term reasoning and memory, since players must remember past states and clues.
Encourage tool use abstraction (move, look, interact, talk).
Offer auditability, since every state and action is recorded in text.
In short: they’re safe sandboxes for experimenting with autonomous AI agents.
LLMs are especially interesting when environments are non-deterministic and require inference. For instance:
A chest may appear in the room description, and the agent may hold a key in inventory—but there is no explicit hint that the key unlocks the chest, or what the exact command syntax should be. LLM reasoning often bridges these gaps by inferring natural connections.
A more challenging case: a chair is described in the text, but no hint suggests you can sit on it. With the right prompting, an LLM can infer that “sit chair” might be a valid command, despite no syntax hint.
This ability to connect context, infer hidden mechanics, and experiment with plausible actions is what makes LLMs uniquely suited to these environments. It also reveals their strengths—and limits—when forced to act without complete information.
My Project: Mistle
To explore this idea, I created Mistle (Machine Intelligence Surviving in Text-Lead Environments)—an agentic AI project designed to survive in the Austrian MUD Silberland for as long as possible while exploring its game world. Mistle connects an LLM to the environment through constrained tools and an observe → decide → act loop. The challenge is not just single-player survival: a multi-user environment introduces additional complexities, such as asynchronous events, other players interacting, shifting world states, and the need for communication strategies.
A MUD is alive. Players may walk into the same room, monsters may attack unexpectedly, or timed events may fire while the agent is mid-reasoning. These dynamics make MUDs especially fascinating testbeds for agent research. I may release Mistle at a later time if certain concerns can be cleared, but for now it serves as a playground for exploring agentic reasoning in chaotic, text-rich worlds.
The Agent Loop: Observe → Decide → Act
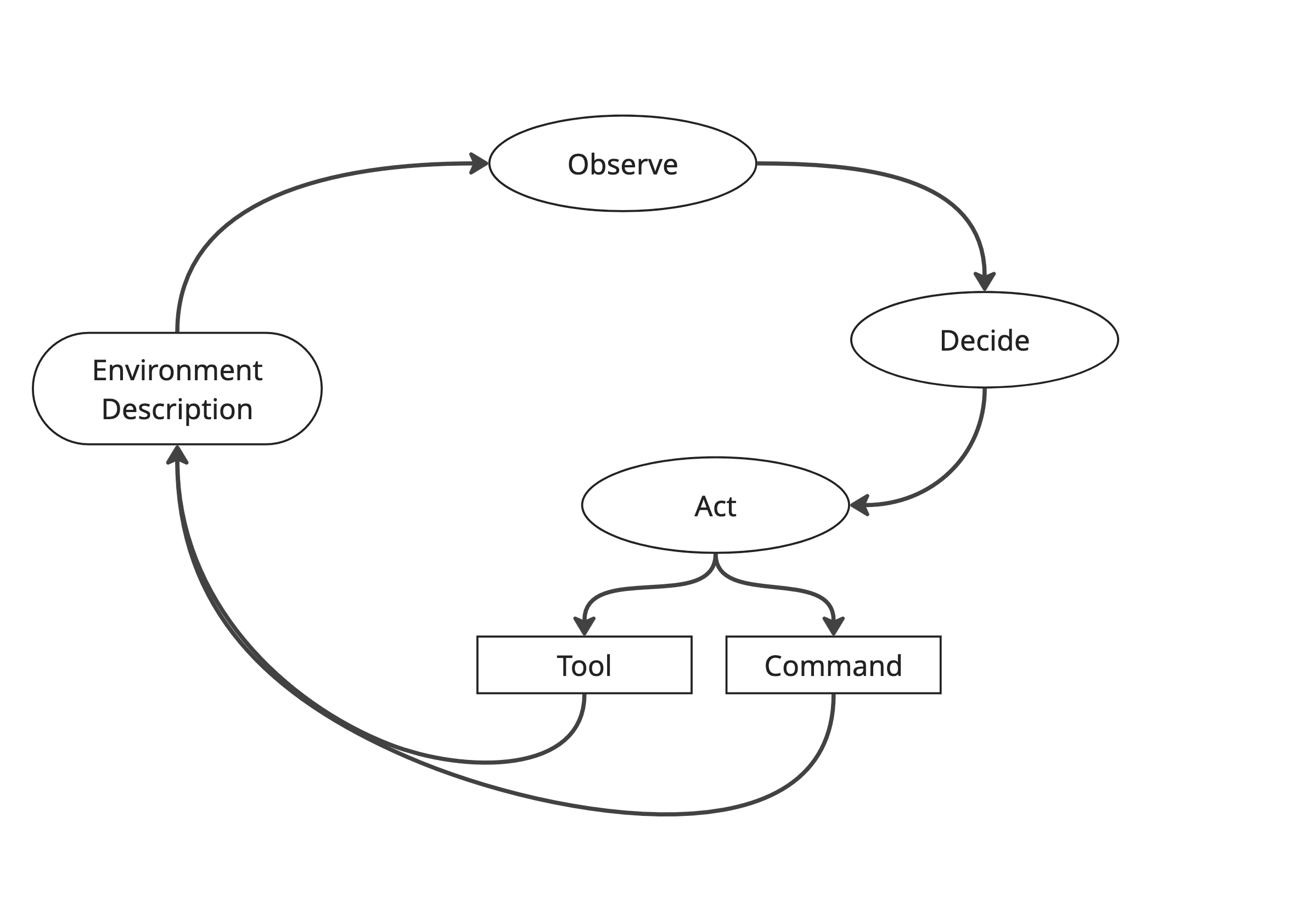
An LLM-driven agent in a text world follows a simple but powerful cycle:
Observe: Ingest text descriptions of the current environment, inventory, and events.
Decide: Use reasoning or planning (deterministic rules, heuristics, or LLM-based strategies) to select the next step.
Act: Issue a command or invoke a tool (e.g., move, look, use item, talk to NPC).
This loop repeats until the agent either succeeds or fails. Crucially, the loop turns free-form text into structured cycles, making results auditable and reproducible.
Tools as Abstractions
While an agent could type arbitrary text commands, it’s more effective to constrain actions into Tools. Tools are deterministic wrappers that:
Sanitize and validate commands (e.g., move north, pick up key).
Reduce prompt complexity by simplifying the action space.
Make runs reproducible and safe, since only certain behaviors are allowed.
Common tools include Look, Move, Explore, and Use. More advanced ones handle dialogue, inventory management, or even communication with other players. By limiting the action set, we make it easier to study agent reasoning and prevent chaotic or invalid commands.
Tools can also be extended. For example, a CombatTool could manage fight/flight logic, while a DialogueTool might constrain conversational exchanges with NPCs or human players. These abstractions balance safety with expressiveness.
Example Episode
Consider an agent dropped into a dungeon:
Text: “You are in a stone chamber. A locked chest sits in the corner.”
The agent observes this description and updates its internal state.
Using an Explore tool, it identifies “chest” as an object of interest.
The agent attempts Use chest → response: “The chest is locked. You need a key.”
It decides to explore adjacent rooms, moving north and east.
In one room, text describes “a rusty key.” The agent picks it up.
Returning, it tries Use chest, key → success.
The chest opens, revealing a clue that advances the game.
Every step is visible in text logs, making it easy to analyze strategies, mistakes, and adaptation. Episodes like this also provide natural benchmarks: Did the agent solve the puzzle efficiently? Did it hallucinate invalid commands? How many steps were wasted?
Why This Matters
Studying LLM-driven agents in text environments reveals both strengths and limitations:
Strengths: natural fit for text reasoning, contextual understanding, puzzle-solving potential, and ability to infer unstated affordances.
Weaknesses: hallucinated commands, short-term memory issues, inefficient exploration, and timing constraints in multi-user environments.
Timing and performance are particularly critical in MUDs. Certain behaviors—like combat—require agents to act within strict time frames. An agent may need to run away before dying, drink a potion at the right moment, or trigger a defensive command instantly. Here, LLM inference speed and agent runtime performance can become bottlenecks. Unlike turn-based puzzles, multi-user or real-time settings punish hesitation.
This is where hybrid strategies may help: reflex-like rules for critical reactions (e.g., auto-flee at low health) combined with slower, deliberate LLM planning for exploration and puzzle solving. Here we can see: Not every problem needs Machine Intelligence to be solved—algorithmic solutions still have their well deserved place.
Challenges & Future Work
Current challenges I work on include:
Hallucination: agents sometimes invent invalid or nonsensical actions, particularly when the environment is underspecified.
Token bloat: large context windows can slow reasoning and inflate costs as environments grow more complex.
Timing/performance: in fast-paced scenarios, especially combat, slow reasoning can cost survival. Real-time reactions remain a bottleneck.
Evaluation: defining clear, comparable success metrics across varied puzzles and dynamic environments is still an open problem.
Disjointed Decision Making: some scenarios require the agent to understand that an action taken five rooms back change the state of the current room and thereby create a gap in the action and consequence loop.
Future directions I currently consider include:
Memory and map-building modules for better navigation and long-term planning.
Belief tracking for more consistent internal world models.
Hybrid architectures that combine reflex-like rules with slower LLM planning.
Benchmark harnesses for comparing strategies across puzzles and worlds.
Extending multi-user settings: handling asynchronous events and richer communication. Here, giving the agent a personality via the LLM has worked especially well—enabling natural interactions with other players while remaining consistent.
Optimizing performance for time-critical actions such as combat, defense, or negotiations.
Achieving all the same with less cost
Closing Thoughts
Text worlds are an ideal arena to explore how AI agents can survive, adapt, and solve problems. My project Mistle demonstrates how this can work in practice—especially in the rich, multi-user world of Silberland. By constraining actions through tools and studying their performance, we can benchmark agentic intelligence in a controlled, language-native environment.
The broader research challenge is not just about beating a game—it’s about testing the limits of reasoning, adaptability, and survival under constraints. Mistle is one step toward that exploration. I may release it in the future; until then, I hope this inspires others to connect LLMs to text adventures or MUDs and observe what unfolds when machines are asked to live in words.